Создание статей для сайта на WordPress может превратиться в настоящее испытание, особенно когда работа связана с большим количеством изображений (как, например, у меня было в статье про линейную интерполяцию в Unity
Я столкнулся с этой проблемой, используя Obsidian для написания контента. Каждый раз мне приходилось вручную сохранять все изображения из готовой заметки, сжимать их, загружать на хостинг. Затем оформлять статью, вставляя каждое изображение отдельно. И это еще хорошо, когда я просто писал непрерывно статью и вставлял картинки, их можно тогда просто отобрать по времени создания из папки с хранилищем. Другое дело, когда я растягивал написание статьи на неопределенное время, в таком случае отобрать изображения для конкретной статьи — становится довольно нетривиальной задачей.
Соответственно, данный процесс отнимал огромное количество времени и сил, превращая удовольствие от написания в рутинную и утомительную работу.
Я решил, что пора что-то менять и автоматизировал все эти действия. В этой статье я поделюсь с вами, как мне удалось упростить процесс создания статей, сделав его более эффективным и приятным. Мы рассмотрим, какие шаги были автоматизированы, какие инструменты использованы и как вы тоже можете внедрить подобное решение для своего сайта на WordPress.
Кстати, данная статья опубликована на сайт как раз по такому способу.
Поиск решения проблемы
Изначально, я хотел найти какое-либо приложение, которое будет это делать за меня. Но сколько бы я ни старался, не гуглил, не искал — не находилось ничего, кроме плагина WordPress Publish, который позволяет автоматизировано постить на сайт текущую статью Obsidian вместе с изображениями.
Собственно на этом можно было бы и остановиться, однако меня не устроили следующие вещи:
- Изображения публикуются с оригинальными наименованиями, которые присваивает Obsidian автоматически. Например: ![[Pasted image 20240723085836.png]]
Я же хочу чтобы картинки назывались у меня определенным наименованием, отражающим суть файла. Плюс к этому, файлы должны быть немного сжаты (т.к. в png они весят больше, чем в jpg, а место на хостинге не резиновое) - Порой я для удобства прописываю разрешение изображения, используя разметку: «Имя изображения|разрешение» — такие файлы плагин вообще не хотел воспринимать (судя по всему из-за символа «|» в наименовании)
Можно было бы форкнуть данный плагин, дописать его под свои нужды и пользоваться. Однако, он написан на JavaScript, который я почти не знаю, поэтому автоматизировать все действия я решил на Python (заодно и попрактиковать данный язык, который сейчас активно изучаю).
Приступаем
Хранилище Obsidian у меня реализовано достаточно просто. В настройках указано, что все заметки создаются в папке «Data», а все изображения в папке «Images»
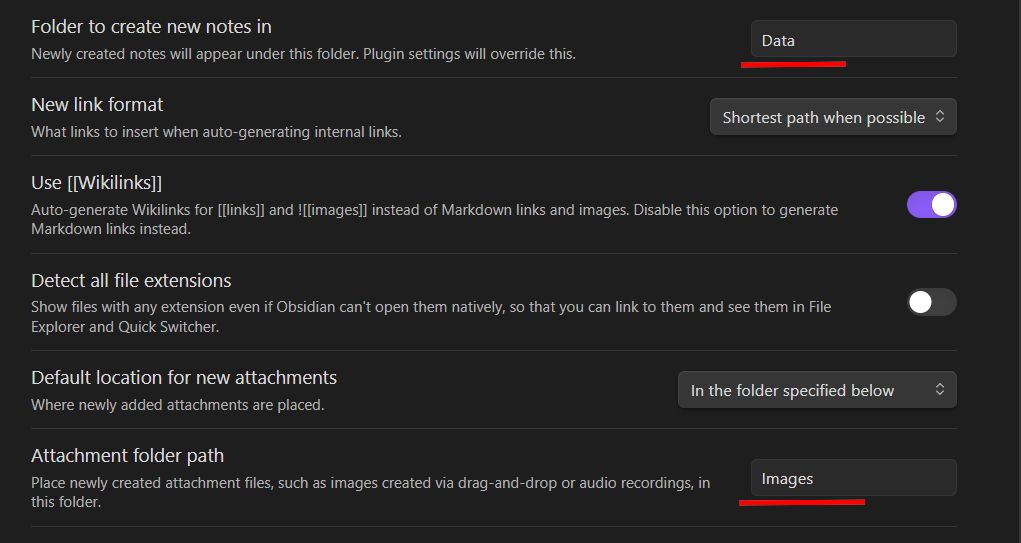
Соответственно, на данную структуру я и ориентируюсь.
Для того чтобы не наводить бардак в текущем хранилище — я создам новое, конкретно для публикации заметок на сайт.
Скрипт на питоне будет перемещать исходный файл в данное хранилище, брать исходные изображения, переименовывать их, сжимать и менять ссылки в данной копии заметки. После чего из этого же хранилища я буду публиковать страницу на сайт и после публикации мне довольно будет легко почистить ненужные файлы, просто удалив заметку из хранилища и все картинки из папки с изображениями.
Поэтому, первым делом, создаем новое хранилище и настраиваем его в точности, как текущее (т.е. заметки в папке Data, картинки в папке Images):

Путь к старому хранилищу у меня: E:\Kostegs\Obsidian_Storage\Storage
Новое хранилище я создал рядом: E:\Kostegs\Obsidian_Storage\Storage_ForSite
Скрипт на Python
Структура скрипта
Теперь приступим к скрипту на Python.
Определим последовательность действий, как должен работать наш скрипт:
- Получить путь к исходному файлу
- Определить из него путь к хранилищу
- Сохранить исходный файл в новое хранилище
- Пропарсить данный исходный файл и найти все файлы изображений
- Каждое изображение сжать и сохранить в новое хранилище с другим наименованием
- В копии исходной заметки, поменять пути к файлам, на новые файлы
После всех этих действий можно уже публиковать заметку.
Я решил для переименования файлов изображений воспользоваться прописыванием нового наименования в исходную ссылку на изображение. Т.е. все изображения, которые я хочу переименовать и которые имеют локальный адрес типа ![[Pasted image 20240806233446.png]] я меняю (при вставке) в исходной заметке на ![[Pasted image 20240806233446.png|Filename-for-site]], т.е. прописываю как должна называться картинка после обработки скриптом, через «Исходное название файла|Новое имя файла». Соответственно, скрипт должен это тоже учесть.
Приступим теперь к написанию данного скрипта.
Начало скрипта
Сперва импортируем нужные библиотеки:
import re # для использования регулярок
import shutil # для операций с файлами
import sys # для получения аргументов запуска скрипта
from pathlib import Path # для работы с путями
from PIL import Image # для сжатия изображенийТеперь напишем точку входа:
if __name__ == '__main__':
# наш скрипт будет принимать 2 аргумента из командной строки
# -путь к исходному файлу
# -путь к хранилищу для сайта
if len(sys.argv) > 2:
file_path = sys.argv[1]
storage_for_site = sys.argv[2]
process_file(file_path, storage_for_site)Копируем исходный файл
Сделаем сперва копирование исходного файла в новое хранилище:
def process_file(file_path, storage_for_site):
# определяю путь к исходному хранилищу
# через 2 parent, т.к. у меня такая структура, выше об этом писал
storage_path = Path(file_path).parent.parent
# определяю имя исходного файла (только имя)
file_name = Path(file_path).name
# пути к папкам Data и Images в новом хранилище
processed_data_path = Path(storage_for_site).joinpath('Data')
compressed_images_path = Path(storage_for_site).joinpath('Images')
# проверяю на существование данных папок, создаю при необходимости
check_folder_exist(processed_data_path)
check_folder_exist(compressed_images_path)
# копирую исходный файл в новое хранилище
dest_file = copy_source_file(file_path, processed_data_path, file_name)Метод check_folder_exist() проверяет — существует ли указанная директория и создаёт ее, если она отсутствует
def check_folder_exist(folder):
if not Path(folder).exists():
Path(folder).mkdir()Метод copy_source_file() копирует исходный файл в новое хранилище:
def copy_source_file(original_file_path, processed_data_path, file_name):
# определяю, куда положить копию и копирую
# это будет Путь к новому хранилищу\Data\имя файла.md
dest_path = Path(processed_data_path).joinpath(file_name)
shutil.copy(original_file_path, dest_path)
return dest_pathПарсим изображения
Отлично, файл скопировали, теперь необходимо из него вытянуть информацию по картинкам. Добавим вызов parse_image_names() далее в метод process_file():
images, content = parse_image_names(dest_file)def parse_image_names(source_file):
# читаем содержимое файла
try:
with open(source_file, 'r', encoding='utf-8') as f:
file_contents = f.read()
except Exception as e:
print(f'Can\'t read the file, because: {e}')
return [], ''
# регуляркой ищем все значения в файле вида ![[Pasted image 20240711090319.png|Timeline_AutoPlay]]
# или ![[Pasted image 20240711090319.png|Timeline_AutoPlay|400]]
# режем их на оригинальное имя: Pasted image 20240711090319.png
# и новое имя: Timeline_AutoPlay
pattern = r'pasted image \d+.\w+\|.[^]|]+'
picture_names = re.findall(pattern, file_contents, re.IGNORECASE)
picture_names = [x.split(r'|') for x in picture_names]
temp_list = ['Name', 'NewName']
finish_list = []
# создаем список словарей вида: {Name : Original name, NewName : new name}
for pict_name in picture_names:
finish_list.append(dict(zip(temp_list, pict_name)))
# возвращаем данный список и содержимое файла
return finish_list, file_contentsТеперь на руках у нас есть список, где лежат все, попадающие под наши критерии, картинки, со старым и новым наименованием
Сжатие изображений:
Для сжатия картинок напишем отдельный метод (будем его вызывать позже), который будет использовать библиотеку Pillow и сжимать наши картинки. Передадим в метод путь к оригинальной картинке (без расширения) и путь к картинке, в которую надо сохранить оригинальную картинку, а также качество:
def compress_img(original_img_path, compressed_image_path, quality):
# открываем исходную картинку
with Image.open(original_img_path, 'r') as img:
# новое расширение будет JPEG
new_filename = f"{compressed_image_path}.jpg"
# сохраняем оригинальную картинку с нужным качеством
try:
img.save(new_filename, quality=quality, optimize=True)
except OSError:
# в случае ошибки, конвертим в RGB
img = img.convert("RGB")
# сохраняем
img.save(new_filename, quality=quality, optimize=True)Дальнейшая обработка картинок
После того как мы получили список картинок из исходного файла, займемся их обработкой:
images, content = parse_image_names(dest_file)
# путь, где лежат изображения изначального хранилища
origin_img_path = Path(storage_path).joinpath('Images')
# шаблон паттерна, по которому мы будем искать наименования типа
# ![[Pasted image 20240711090319.png|Timeline_AutoPlay]] в исходном
# файле и полностью их заменять на путь к новой (сжатой) картинке
pattern = r'!\[+img_name.+\]'
for image in images:
# путь к исходной картинке (без расширения)
source_image = Path(origin_img_path).joinpath(image['Name'])
# путь к конечной картинке (без расширения)
dest_image = Path(compressed_images_path).joinpath(image['NewName'])
# сжимаем исходную картинку и сохраняем по указанному конечному
# пути с расширением .jpg
compress_img(source_image, dest_image, 80)
# меняем в шаблоне паттерна поиска img_name на
# конкретное название исходной картинки
current_pattern = pattern.replace('img_name', image['Name'])
# в содержимом файла делаем подмену наименований типа
# ![[Pasted image 20240711090319.png|Timeline_AutoPlay]] на
# ![[TimeLine_AutoPlay.jpg]]
content = re.sub(current_pattern, f'![[{image['NewName']}.jpg]]', content)
# записываем данное содержимое в конечный файл
with open(dest_file, 'w', encoding='utf-8') as f:
f.write(content)Проверяем скрипт
Запустим теперь данный скрипт и проверим, как он работает. Для этого в терминале запускаем этот скрипт с аргументами: Исходный файл — Новое хранилище.

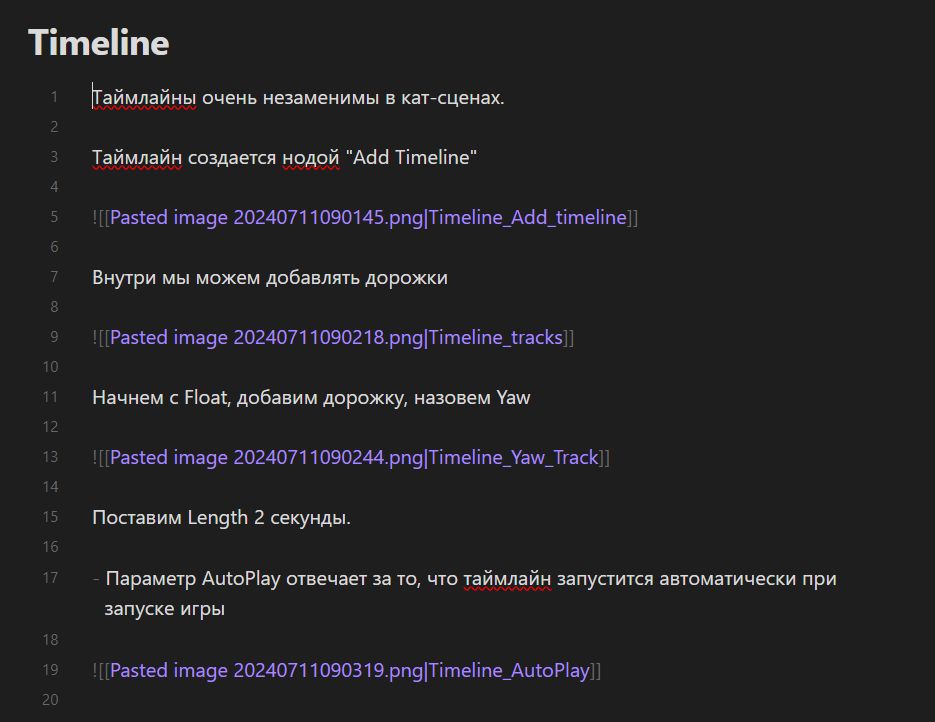
Исходный файл выглядит вот так:
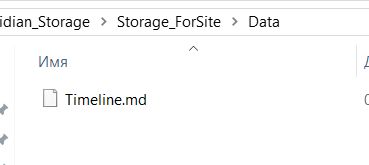
Заходим в хранилище для сайта, видим, что в папке Data создалась копия исходного файла:
В папку Images скопированы исходные изображения, названы так, как я хотел и находятся в формате JPEG
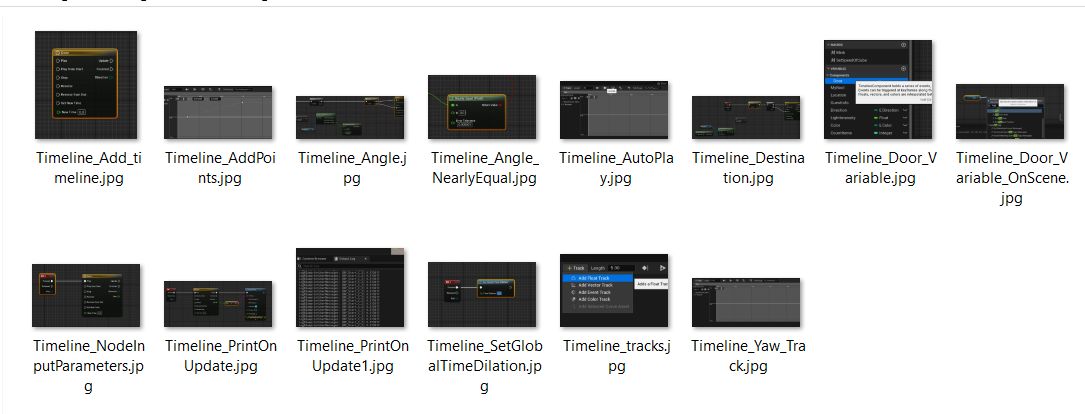
В копии файла заменены все ссылки к изображениям на нужные:
Автоматизация запуска скрипта
Так как если автоматизировать, то уже до конца — сделаем так, чтобы запуск данного скрипта происходил автоматизировано и нам не приходилось постоянно вбивать аргументы в командную строку.
Чтобы это сделать, нужно написать небольшой код на JavaScript и воспользоваться плагином для Obsidian под названием Templater.
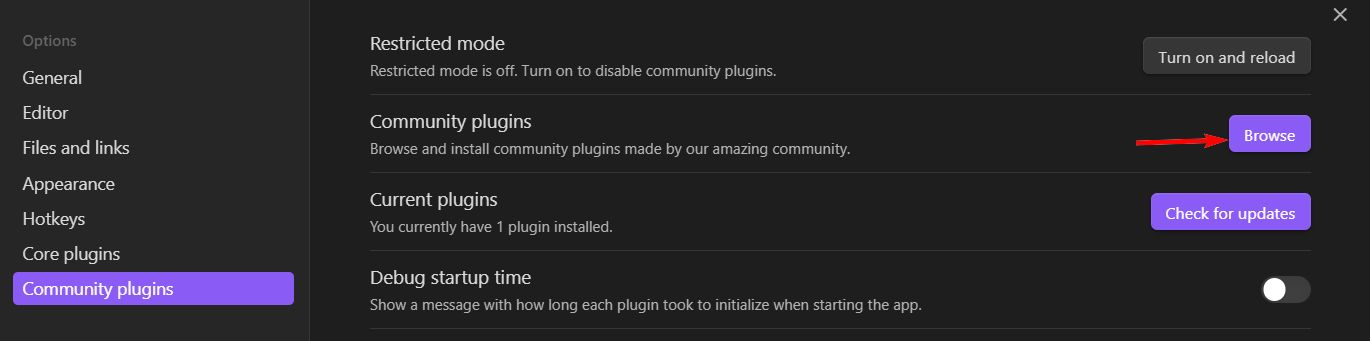
Сперва установим сам плагин. Идем в Community Plugins и жмем кнопку Browse:
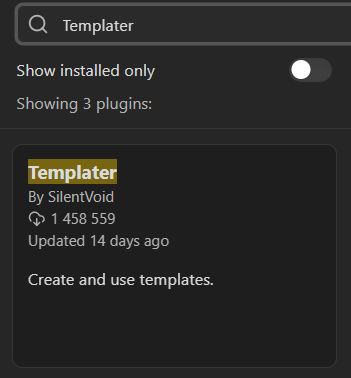
Выбираем там Templater и устанавливаем его. Т.к. Python-скрипт мы будем вызывать из исходного хранилища, то и плагин устанавливаем тоже туда.
После установки плагина на панели в Obsidian появляется возможность его запустить:
Пока еще ничего работать не будет. Сперва настроим данный плагин. Укажем папку, где будут лежать скрипты:
И создадим данную папку в хранилище.
В данной папке теперь создадим файл с расширением .js, назовем его, например, process_note_for_site.js и напишем в него следующий код:
<%*
// Импортируем функцию exec из модуля child_process,
// чтобы можно было запускать команды оболочки
const { exec } = require('child_process');
// Получаем путь к текущему файлу Obsidian
const filePath = tp.file.path();
// Запускаем Python-скрипт с передачей пути к текущему файлу в качестве первого
// аргумента и пути к хранилищу для сайта - вторым аргументом
exec(`python E:/Dev/Python/Process_Images_Obsidian/start.py "${filePath}" "E:/Kostegs/Obsidian_Storage/Storage_ForSite/"`, (error, stdout, stderr) => {
// при ошибке покажем данную ошибку на экран
if (error) {
alert(`Error: ${error}`);
return;
}
});
%>Теперь, если нажать на плагин Templater на панели, то мы видим наш JS-скрипт, при нажатии на него, он запускает наш скрипт на Python

Проверяем — всё работает. Исходный файл скопирован, картинки заменены, всё отлично.
Авто-публикация на сайт
Осталось только установить плагин для авто-публикации статьи на сайт в наше новое хранилище.
В хранилище, куда отправляются отредактированные данные (т.е. не в основном) переходим в Community Plugins и ищем там плагин WordPress Publish:
Устанавливаем его и настраиваем:
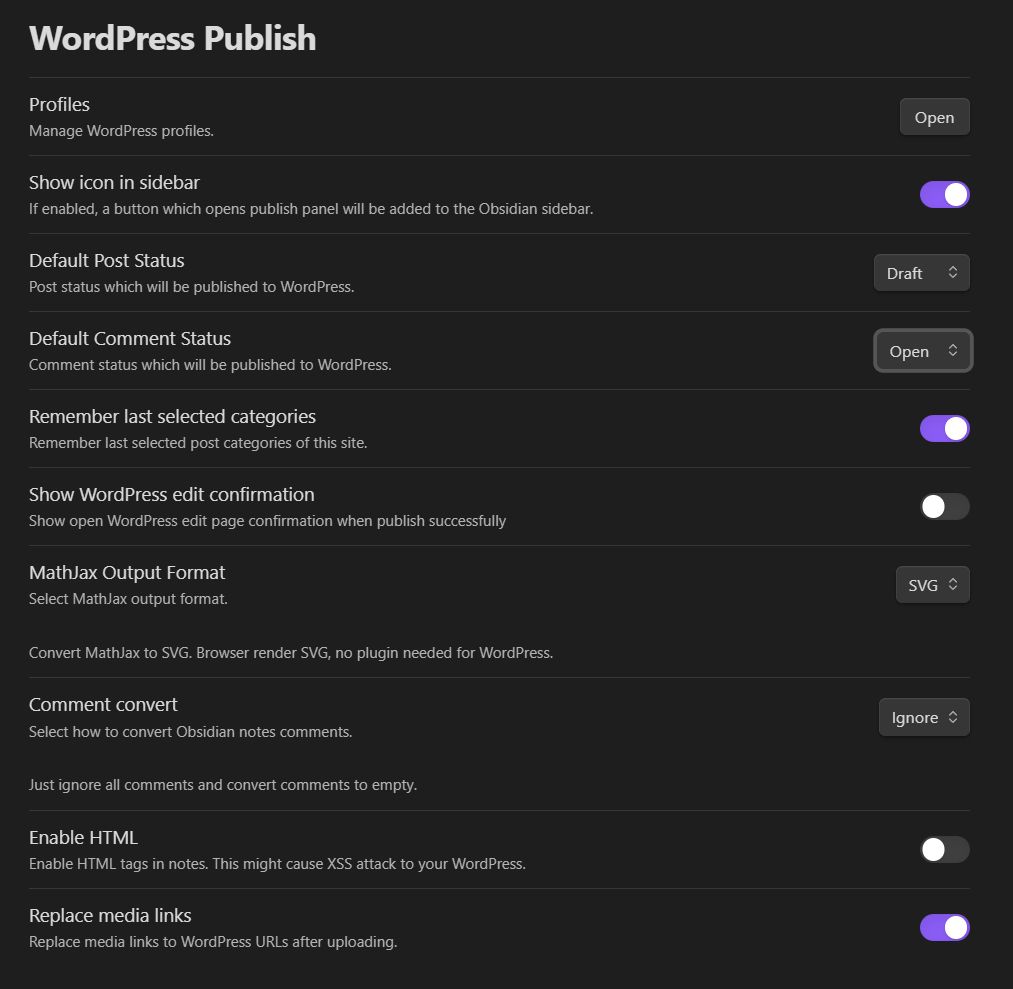
Обязательно выделяем «Show Icon in Sidebar» чтобы иконка данного плагина появилась в сайдбаре обсидиана:
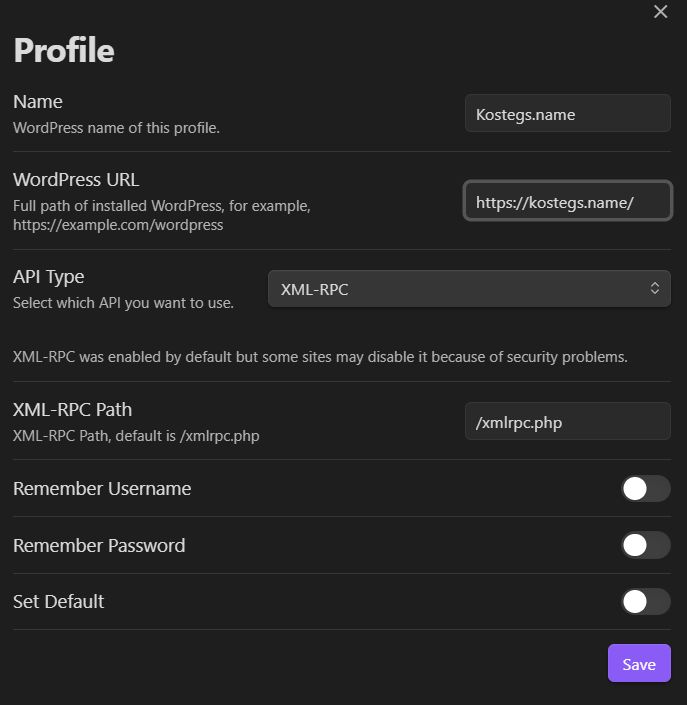
Осталось только настроить профиль:

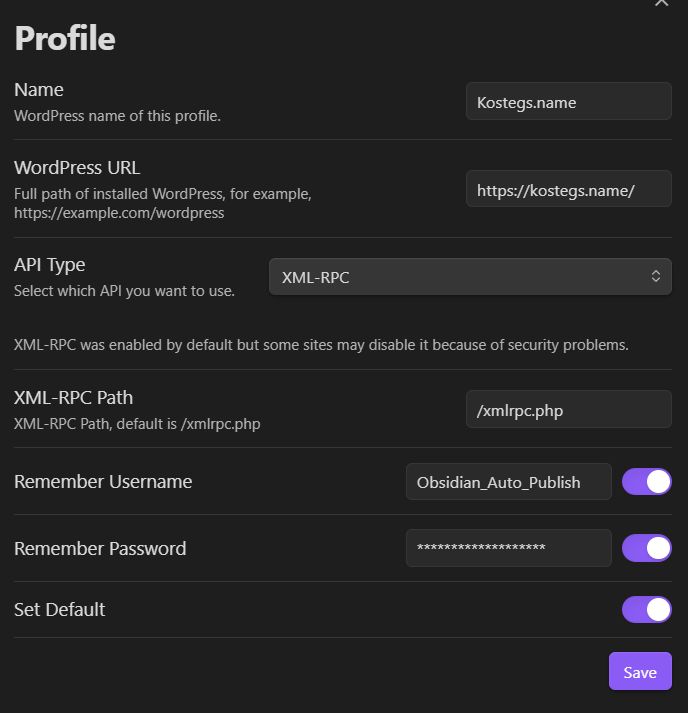
Прописываем название профиля, путь к сайту. Выбираем Api Type, как XML-RPC
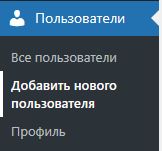
Так как мы не хотим палить свой пароль от админки стороннему софту, то создадим данному плагину отдельного пользователя.
Для этого в админке сайта зайдем в Пользователи — Добавить нового пользователя
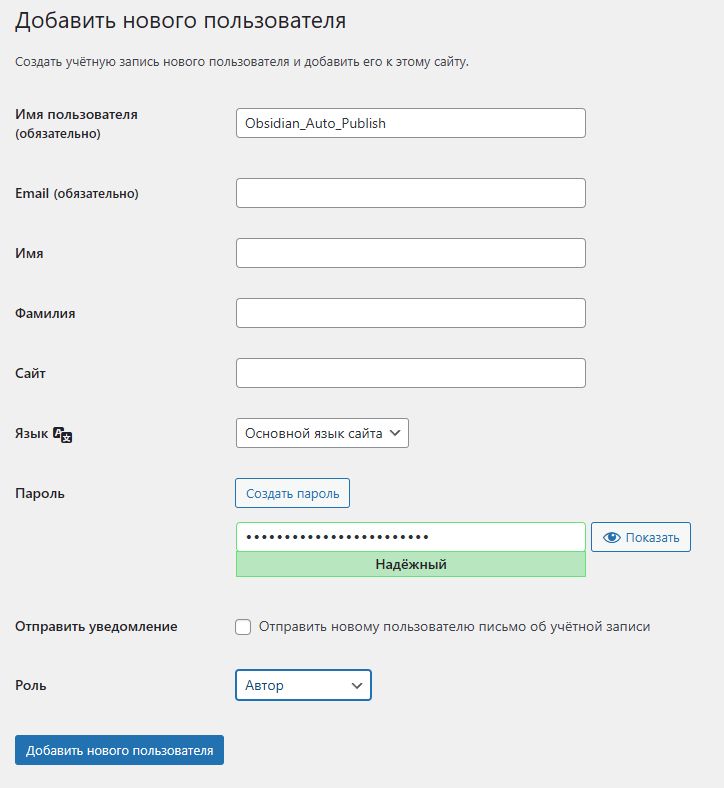
Плюсом к этому, там же, в админке, зайдем в данного пользователя и добавим ему пароль приложений, чтобы использовать его для плагина (даже зная данный пароль в админку сайта попасть невозможно через web-интерфейс):
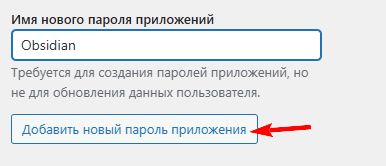
Пароль будет сгенерирован, нам останется его только скопировать и в настройке профиля плагина указать данного пользователя и пароль:
Теперь, когда мы находимся внутри статьи достаточно нажать на иконку плагина в сайдбаре:
Нам открывается окно, где мы настраиваем публикацию:
- Post status — черновик
- Comments — комментарии открыты
- Post type — пост
- Category — категория, куда отнести данный пост
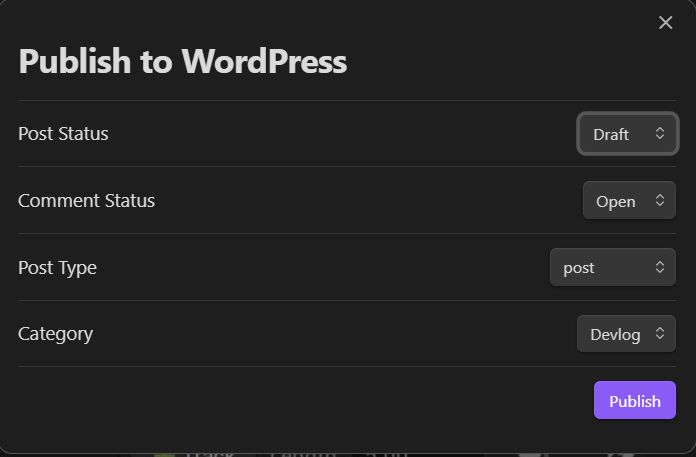
При нажатии кнопки Publish — пост публикуется на сайт, в формате черновика:
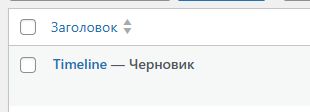
Как видим, все картинки опубликовались тоже:
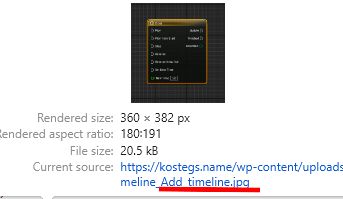
Причем с нашими наименованиями, которые мы подготовили до этого скриптом
Заключение
Итак, после нескольких нехитрых действий — процесс публикации заметок на сайт осуществляется ровно нажатием пары кнопок.
Данную автоматизацию процесса написания и оформления статей для сайта на WordPress я только начал использовать, но, чувствую, она уже становится для меня настоящим спасением. Я смог превратить трудоемкий и рутинный процесс в быструю и эффективную процедуру. Благодаря этому решению я экономлю много времени и усилий, которые теперь могу направить на создание более качественного и интересного контента.
Надеюсь, что мой опыт и описанные методы автоматизации помогут и вам облегчить вашу работу. Не бойтесь экспериментировать и внедрять новые инструменты – это всегда приносит свои плоды. Теперь я уверен, что создание статей для WordPress не должно быть обременительным занятием, а может стать увлекательным и творческим процессом. Удачи и вдохновения в ваших начинаниях!
P.S. Код скрипта на Python находится на гит-хабе: https://github.com/kostegs/Process_Images_Obsidian